Predicting Network Traffic Matrix Using LSTM with Keras (part 1)
October 3, 2019 in Blogs

Please find the original research paper here
More details can be found here
In this article we are going to explain step by step how to implement an online traffic matrix predictor using Recurrent Neural Networks, specifically, the Long Short Term Memory architecture. At the end of this post, you will:
- Understand the importance of Traffic Matrix (TM) prediction
- Know what LSTM networks are and understand how they work
- Be able to implement an LSTM in Keras to perform matrix prediction
NoteThe techniques explained in this post are not restricted to traffic matrix in any way. They can be trivially generalized to any kind of matrix (eg. prediction of next frame in a video).
Content
- Why predicting traffic matrix is important in communication networks?
- Neural Networks for Traffic Matrix Prediction
- Recurrent Neural Networks
- Long Short Term Memory Recurrent Neural Networks
- References
Why predicting traffic matrix is important in communication networks?
Well, as you probably know, computer networks and communication networks in general, like the Internet, have limited resources in term of bandwidth, computing power of the forwarding elements (routers, switches ..), computing power of network middleboxes, etc. Thus, in order to scale and support more users, operators need to optimize their resource allocation.
Having an accurate and timely network Traffic Matrix (TM) is essential for most network operation/management tasks such as traffic accounting, short-time traffic scheduling or re-routing, network design, long-term capacity planning, and network anomaly detection. For example, to detect DDoS attacks in their early stage, it is necessary to be able to detect high-volume traffic
Neural Networks for Traffic Matrix Prediction
Neural Networks (NN) are widely used for modeling and predicting network traffic because they can learn complex non-linear patterns thanks to their strong self-learning and self- adaptive capabilities. NNs are able to estimate almost any linear or non-linear function in an efficient and stable manner, when the underlying data relationships are unknown. The NN model is a nonlinear, adaptive modeling approach which, unlike the traditional prediction techniques such as ARMA, ARAR or HotWinters, relies on the observed data rather than on an analytical model. The architecture and the parameters of the NN are determined solely by the dataset. NNs are characterized by their generalization ability, robustness, fault tolerance, adaptability, parallel processing ability, etc
Recurrent Neural Networks
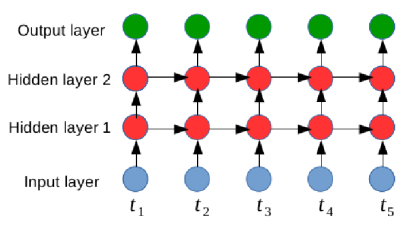
There are two classes of neural networks: Feed Forward Neural Networks (or FNNs) and Recurrent Neural Networks or (RNNs). FNNs can provide only limited temporal modeling by operating on a fixed-size window of TM sequence. They can only model the data within the window and are unsuited to handle historical dependencies. By contrast, recurrent neural networks or deep recurrent neural networks (figure 1) contain cycles that feed back the network activations from a previous time step as inputs to influence predictions at the current time step (figure 2). These activations are stored in the internal states of the network as temporal contextual information [1]. However, training conventional RNNs with the gradient- based back-propagation through time (BPTT) technique is difficult due to the vanishing gradient and exploding gradient problems. The influence of a given input on the hidden layers, and therefore on the network output, either decays or blows up exponentially when cycling around the networks recurrent connections.
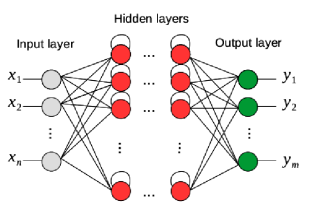
These problems limit the capability of RNNs to model the long range context dependencies to 5–10 discrete time steps between relevant input signals and output.
Long Short Term Memory Recurrent Neural Networks
The architecture of LSTMs is composed of units called memory blocks. A memory block contains memory cells with self-connections storing (remembering) the temporal state of the network in addition to special multiplicative units called gates to control the flow of information. Each memory block contains an input gate to control the flow of input activations into the memory cell, an output gate to control the output flow of cell activations into the rest of the network and a forget gate.
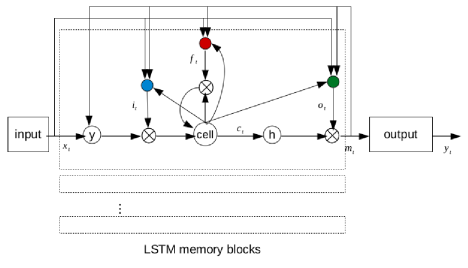
The forget gate scales the internal state of the cell before adding it back to the cell as input through self recurrent connection, therefore adaptively forgetting or resetting the cells memory. The modern LSTM architecture also contains peephole connections from its internal cells to the gates in the same cell to learn precise timing of the outputs
References
Sak, Hasim, Andrew W. Senior, and Franoise Beaufays. ”Long shortterm memory recurrent neural network architectures for large scale acoustic modeling.” Interspeech. 2014.
Felix A. Gers, Nicol N. Schraudolph, and Jurgen Schmidhuber, Learning precise timing with LSTM recurrent networks, Journal of Machine Learning Research , vol. 3, pp. 115143, Mar. 2003.